首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出,
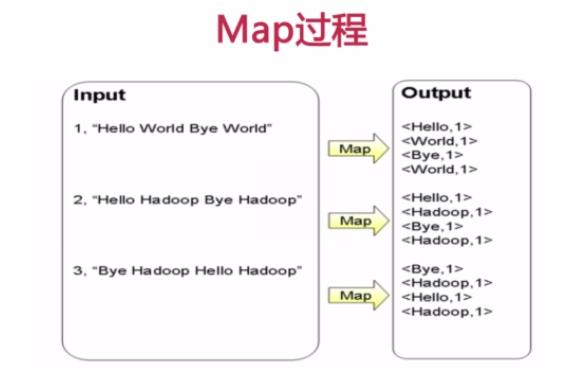
Map过程首先是多个map并行提取多个句子里面的单词然后分别列出来每个单词,出现次数为1,全部列举出来
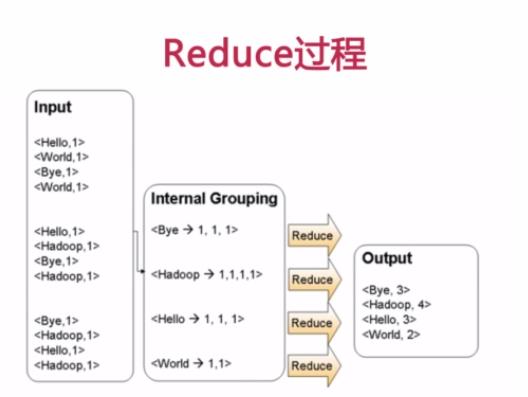
Reduce过程首先将相同key的数据进行查找分组然后合并,比如对于key为Hello的数据分组为:<Hello, 1>、<Hello,1>、<Hello,1>,合并之后就是<Hello,1+1+1>,分组也可以理解为reduce的操作,合并减少数据时reduce的主要任务,叠加运算之后就是<Hello, 3>所以最后可以输出Hello 3,这样就完成了一轮MapReduce处理
WordCount.java代码如下:
1 import java.io.IOException; 2 import java.util.Iterator; 3 import java.util.StringTokenizer; 4 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.LongWritable; 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapred.FileInputFormat;10 import org.apache.hadoop.mapred.FileOutputFormat;11 import org.apache.hadoop.mapred.JobClient;12 import org.apache.hadoop.mapred.JobConf;13 import org.apache.hadoop.mapred.MapReduceBase;14 import org.apache.hadoop.mapred.Mapper;15 import org.apache.hadoop.mapred.OutputCollector;16 import org.apache.hadoop.mapred.Reducer;17 import org.apache.hadoop.mapred.Reporter;18 import org.apache.hadoop.mapred.TextInputFormat;19 import org.apache.hadoop.mapred.TextOutputFormat;20 21 public class WordCount {22 23 public static class Map extends MapReduceBase implements24 Mapper {25 private final static IntWritable one = new IntWritable(1);26 private Text word = new Text();27 28 public void map(LongWritable key, Text value,29 OutputCollector output, Reporter reporter)30 throws IOException {31 String line = value.toString();32 StringTokenizer tokenizer = new StringTokenizer(line);33 while (tokenizer.hasMoreTokens()) {34 word.set(tokenizer.nextToken());35 output.collect(word, one);36 }37 }38 }39 40 public static class Reduce extends MapReduceBase implements41 Reducer {42 public void reduce(Text key, Iterator values,43 OutputCollector output, Reporter reporter)44 throws IOException {45 int sum = 0;46 while (values.hasNext()) {47 sum += values.next().get();48 }49 output.collect(key, new IntWritable(sum));50 }51 }52 53 public static void main(String[] args) throws Exception {54 JobConf conf = new JobConf(WordCount.class);55 conf.setJobName("wordcount");56 57 conf.setOutputKeyClass(Text.class);58 conf.setOutputValueClass(IntWritable.class);59 60 conf.setMapperClass(Map.class);61 conf.setCombinerClass(Reduce.class);62 conf.setReducerClass(Reduce.class);63 64 conf.setInputFormat(TextInputFormat.class);65 conf.setOutputFormat(TextOutputFormat.class);66 67 FileInputFormat.setInputPaths(conf, new Path(args[0]));68 FileOutputFormat.setOutputPath(conf, new Path(args[1]));69 70 JobClient.runJob(conf);71 }72 } 将此java文件上传到服务器后,首先要进行编译,如果是eclipse会自动完成,如果没有配置开发环境需要手动对源文件进行编译,命令如下:
javac -classpath /hadoop/hadoop-1.2.1/hadoop-core-1.2.1.jar:/hadoop/hadoop-1.2.1/lib/commons-cli-1.2.jar WordCount.java
编译的时候需要制定上面两个jar包,编译完成之后除了生成WordCount.class字节码之外还有WordCount$Map.class和WordCount$Reduce.class,我们知道这两个文件是内部类Map和Reduce生成的
然后开始对class文件打包生成wordcount.jar
jar -cvf wordcount.jar *.class

现在就打包生成了wordcount.jar文件
接下来可以通过传给main方法参数执行参数是两个字符串,分别为args[0]和args[1],可以把它放到文件中进行输入,那么可以在hdfs文件系统中建立两个文件file01和file02并写入内容,依次执行命令:
$ echo "Hello World Hello Java" > file01$ echo "Hello World Hello Hadoop" > file02$ hadoop fs -mkdir input$ hadoop fs -put file0* input/
现在hdfs文件系统中/user/用户名/input下就有两个文件file01和file02,同样我们可以用命令查看文件的存在性和内容
接下来就可以提交任务用hadoop来运行jar包中的函数进行数据处理了
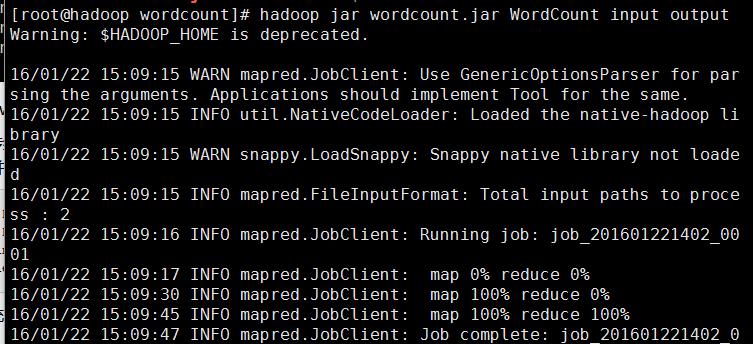
hadoop jar wordcount.jar WordCount input output
WordCount代码jar包里的主类,input是传入的文件作为参数,output参数就是hadoop作业完毕之后结果存放目录,开始执行会看到map和reduce的处理进度
处理完毕后,通过hadoop fs -ls output/ 查看生成的结果文件是否存在
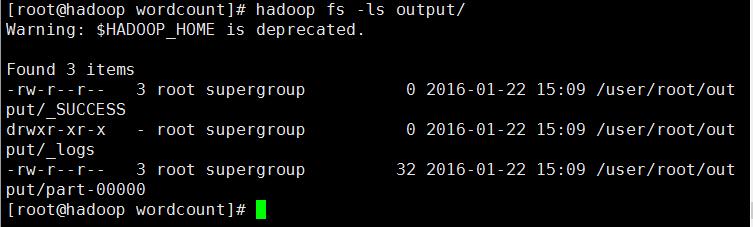
通过结果可以看到任务执行正常并输出了结果文件,可以用hadoop fs -get output localdata将文件传到本地查看,也可以执行下面命令查看文件的内容
hadoop fs -cat output/part-00000
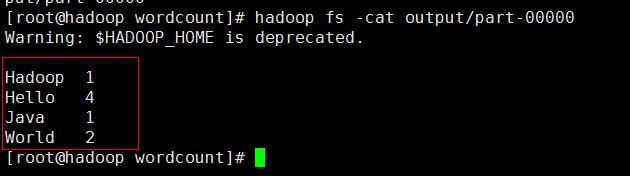
可以看到结果按顺序统计出来了,到这里一个简单的WordCount程序就手动开发成功了